- ITソリューショントップ
-
製品・ソリューション
-
ダイキンのIT
 製造業向けITソリューション
製造業向けITソリューション  建設業務改善ソリューション
建設業務改善ソリューション  ビル管理業務支援 DK-CONNECT BM
ビル管理業務支援 DK-CONNECT BM FILDER CeeD TOP
FILDER CeeD TOP  FILDER CeeD 電気 TOP
FILDER CeeD 電気 TOP  Rebro D TOP
Rebro D TOP  データ・サイエンス・ソリューション Pipeline Pilot
データ・サイエンス・ソリューション Pipeline Pilot  ライフサイエンス向けソフト Discovery Studio
ライフサイエンス向けソフト Discovery Studio 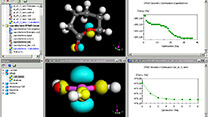 マテリアルサイエンス向けソフト Materials Studio
マテリアルサイエンス向けソフト Materials Studio 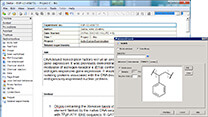 電子実験ノート
電子実験ノート 総合3DCG 制作ソフト Maya
総合3DCG 制作ソフト Maya  総合3DCG 制作ソフト 3ds Max
総合3DCG 制作ソフト 3ds Max  総合3DCG 制作ソフト MODO
総合3DCG 制作ソフト MODO  アニメーション制作ソフト Toon Boom
アニメーション制作ソフト Toon Boom 
データ・サイエンス・ソリューション
Pipeline Pilot
BIOVIA Pipeline Pilot Documents and Text
多くの研究者は、学術誌の記事、特許、社内レポートなどの膨大な量の非構造化データから、有効な情報を識別、処理、抽出するという課題に日々直面しています。従来からの情報源の他にも、Web サイト、Twitter や Facebook などの新しいメディアが加わり、こうした新しいデータソースから情報を抽出することが、競争で優位に立つための鍵となる可能性があります。
Documents and Text Collection は、この氾濫するデータの処理を支援するものであり、これを活用することにより、日常業務で取り扱うドキュメントに含まれる必要な情報を取得、処理、保存することができます。Documents and Text Collection は以前の Text Analytics Collection と ChemMining Collection を組み合わせたもので、内部および外部のソースから重要なドキュメントを識別する機能、そのドキュメントから適切な情報を抽出する機能、さらにその情報を組み合わせて分析し提示する機能などの包括的な機能を提供することにより、一次的な研究結果を補強し、重大な意思決定を支援します。Documents and Text Collection は、中核となる幅広いテキストマイニング機能のセットだけでなく、テキスト内の化合物名を認識し、構造オブジェクトに変換するという専門的機能も備えています。
Documents and Text Collection の機能
- PubMed、US PTO や EPO の特許データベース、Twitter、Bing、Web サイト、SharePoint ドキュメントなどのローカルファイルの検索、およびサードパーティ製の検索エンジンとの統合により、最も重要で価値のあるドキュメントの発見を支援
- 語句検索、ワイルドカード検索、一般名とシノニムのマッチングが可能な単一のクエリ言語を使用した、複数のデータソースの同時検索が可能で、検索式の作成や保守も効率的に実行可能
- 重要なコンセプトを抽出する事により、ドキュメントやオンライン資料中の関係性を特定することが可能で、これによって競合他社の情報が得られると共に、一次的な研究結果をサポート
- 進行中のプロジェクトにおいて、途中経過をレビューするために主要なドキュメントのデータベースを検索可能な形で作成
- テキスト中の化合物名を識別し、OpenEye の Name to Structure の変換システムを使用して構造に変換することにより、化合物を検索可能なドキュメントデータベースを作成
- コンテンツを既存の Microsoft Word ドキュメントに追加することによる、定形ドキュメントの定期的な作成の効率化が可能で、ミスが発生しやすい手作業によるドキュメント編集作業を削減
- リッチでインタラクティブなレポートを作成し、ドキュメントやテキスト分析の検索およびマイニングを実施(専門可視化ツールの Tag Cloud などが含まれる)
お気軽にお問い合わせください
 電話でお問い合わせ
電話でお問い合わせ
- 東京(担当:SATグループ)
- 03-3520-3082
受付時間 9:00-17:30(土・日・祝除く)